Platform
Training & Inference
Train models on fully managed infrastructure and serve them with low-latency inference - from behavior cloning to production endpoints. No GPU clusters to maintain.
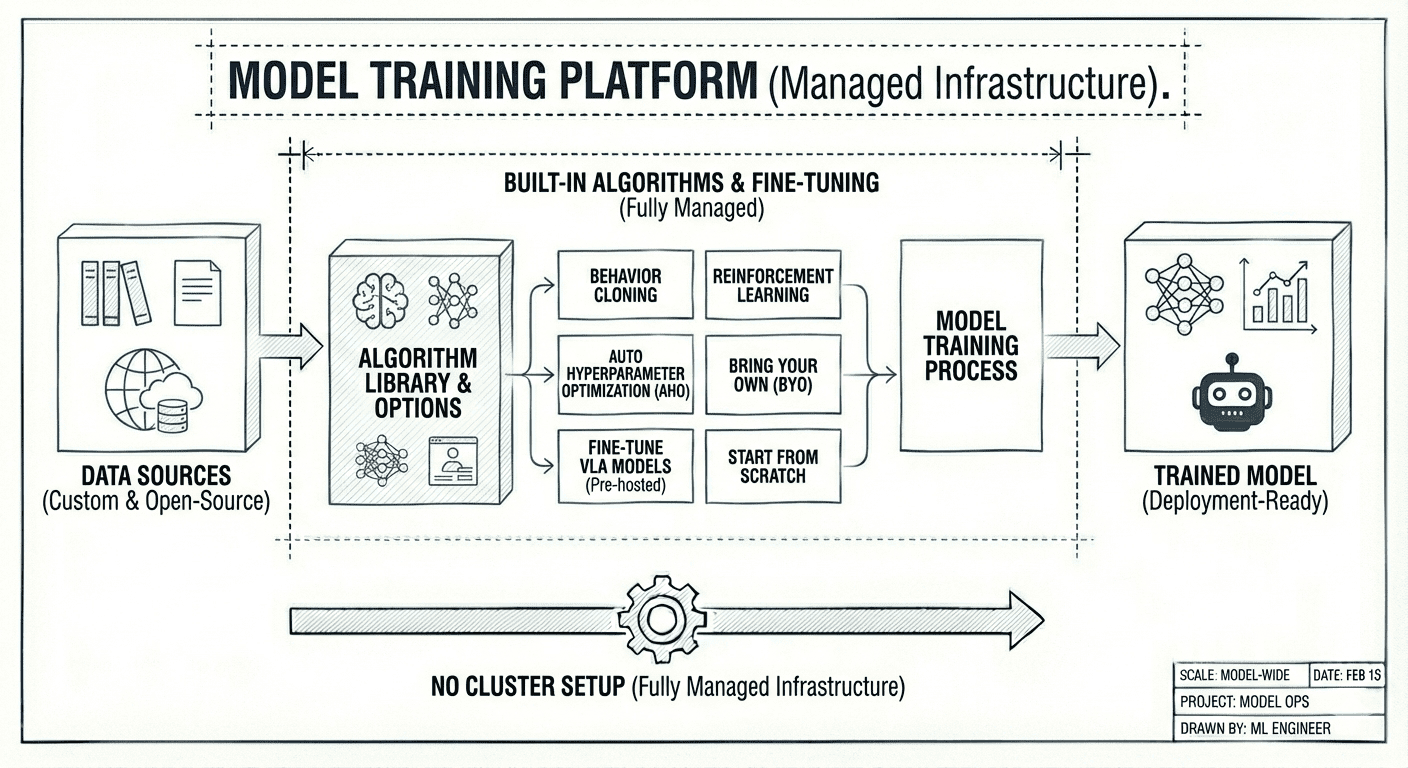
Model training
Train models on your own data with a built-in library of algorithms such as behavior cloning, reinforcement learning, automated hyperparameter optimization or bring your own. Fine-tune pre-hosted open-source VLA models or start from scratch. Fully managed infrastructure, no cluster setup.
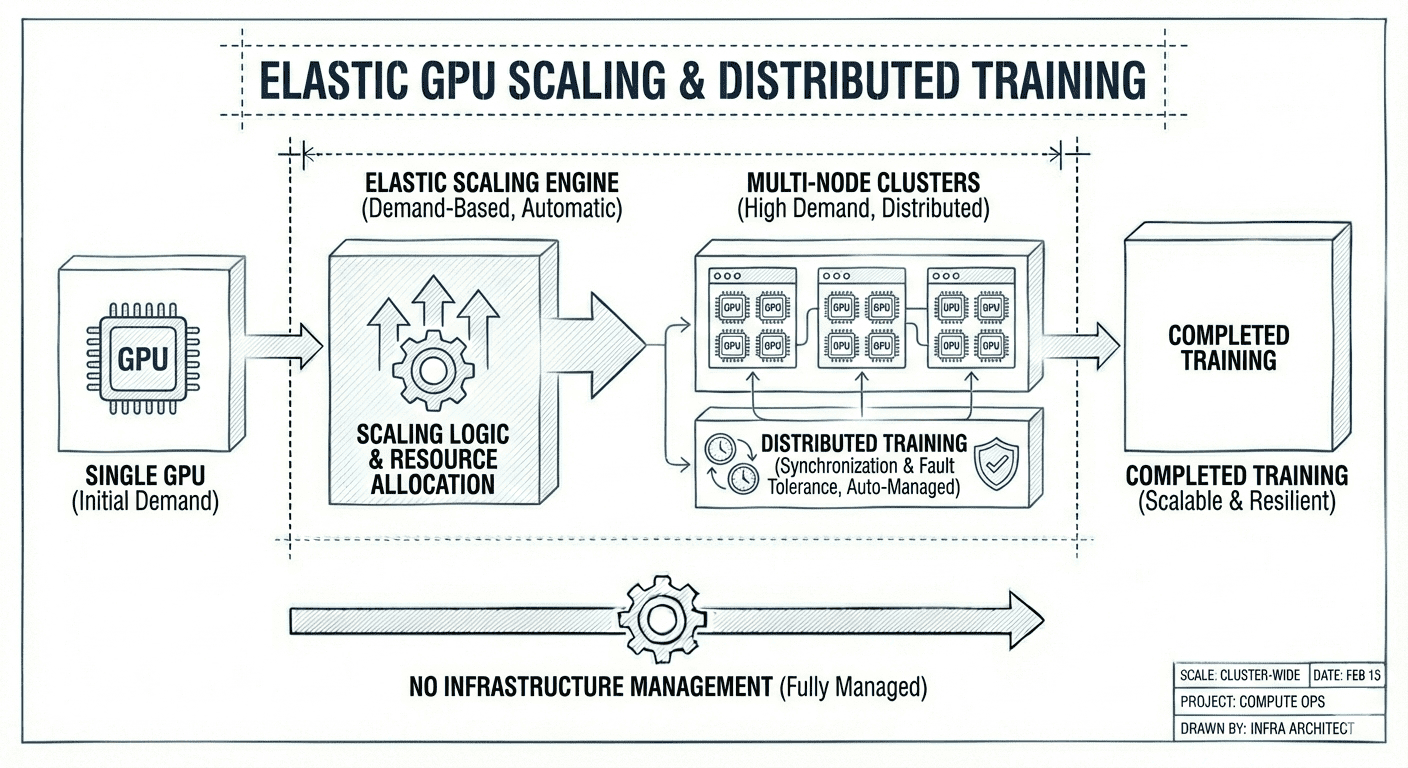
Elastic GPU scaling
Scale from a single GPU to multi-node clusters based on training demand. Distributed training handles synchronization and fault tolerance automatically - no infrastructure management required.
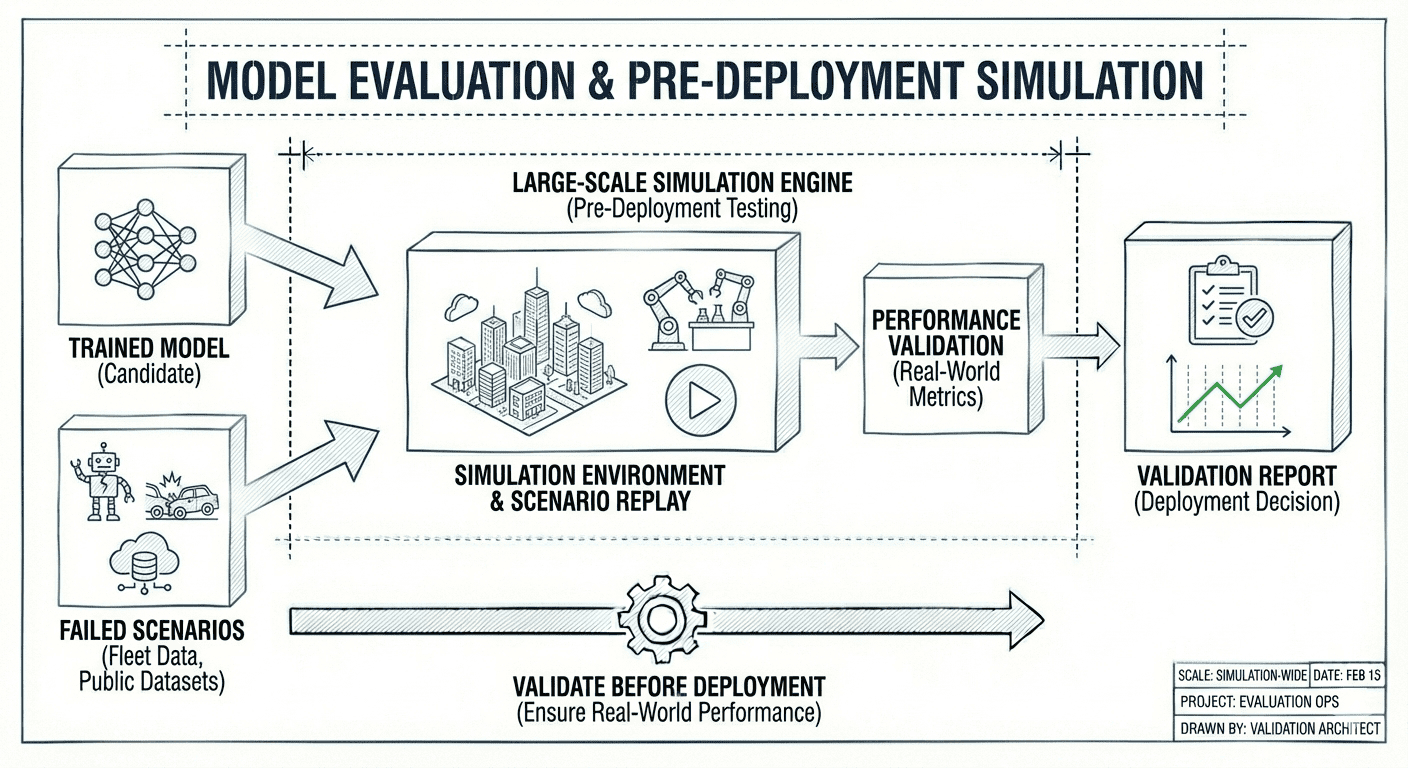
Model evaluation
Evaluate trained models in large-scale simulation before deployment. Test against failed scenarios from your fleet data or public datasets to validate real-world performance.
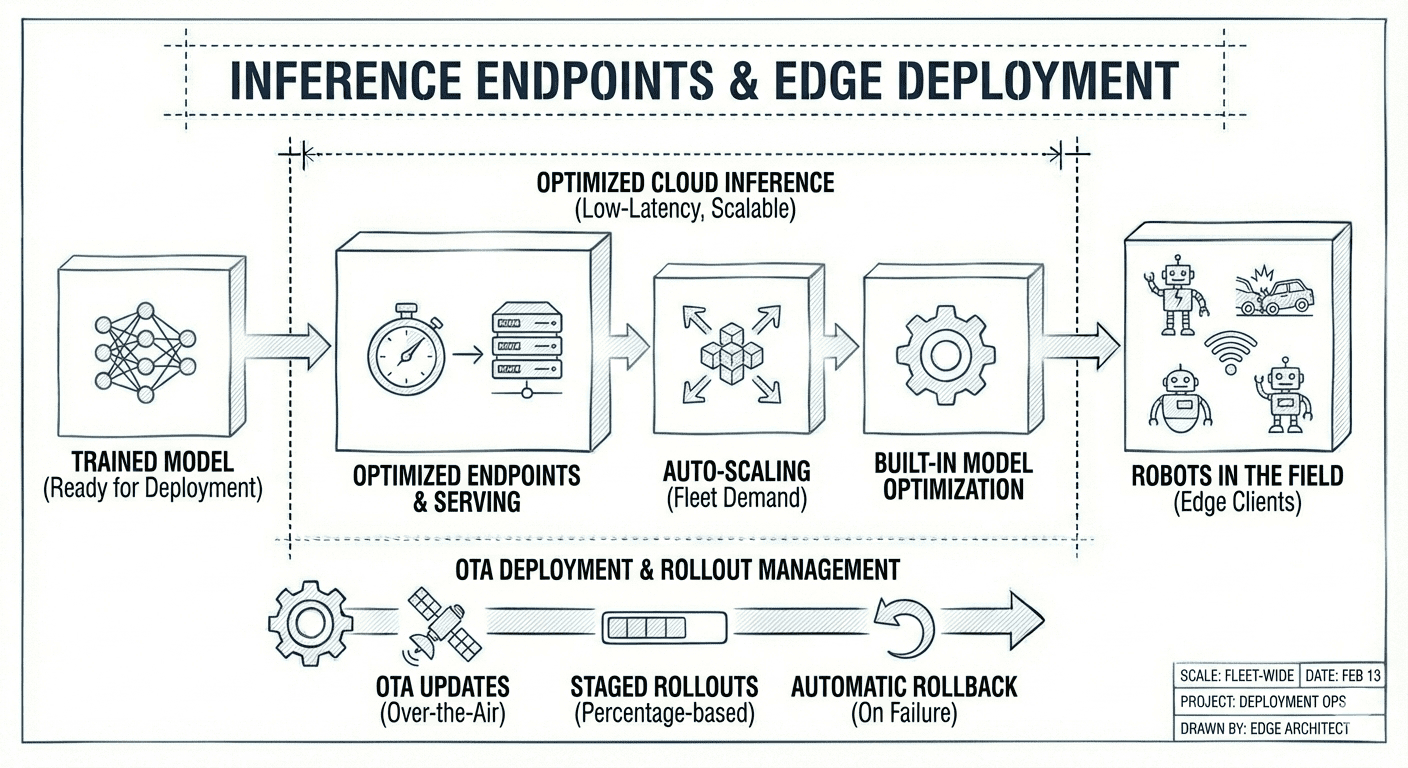
Inference endpoints
Purpose-built cloud inference for robots in the field. Optimized endpoints deliver minimal round-trip latency to edge clients, scale automatically with fleet demand, and serve models efficiently with built-in optimization. Deploy to your fleet with OTA updates, staged rollouts, and automatic rollback on failure.